<del id="aymay"></del> 數據挖掘就是從存放在數據庫、數據倉庫或者其他信息庫中的大量數據中挖掘有趣知識的過程。它是在多種數據存儲方式的基礎上,借助有效的分析方法和工具,從傳統的事務型數據庫功能(增加、刪除、修改、查詢、統計等)背后,獲得更深層次的信息。在數據挖掘技術的不斷發展過程中,如何將數據挖掘(DM)系統與數據庫(DB)系統和數據倉庫(DW)系統緊密耦合(所謂耦合,即是數據挖掘系統和數據庫或者數據倉庫的集成程度)在一起是始終困擾著人們設計一個好的數據挖掘工具的最大問題。從最初的不耦合到松散耦合再到半緊密耦合,人們一直尋求著如何將DM系統平滑的集成到DB/DW中(即緊密藕合)。目前眾多數據挖掘系統、數據挖掘工具中,大部分都是實現一個與數據倉庫系統獨立開來的數據挖掘系統,這樣便使得數據挖掘過程中要花費大量的時間進行數據加載轉換,算法運行時間長、效率低,特別是面對當前數據倉庫中保存的海量數據時,更是效率低下。
文中在已有的數據挖掘系統體系基礎上,應用數據挖掘系統與數據倉庫系統緊密耦合的策略,提出了嵌入式數據挖模型,把數據挖掘系統和整個數據挖掘流程完全控制在數據倉庫系統中,從而大大提高數據挖掘的效率。并且針對市面的一些用于銀行卡業務的數據挖掘系統過于繁瑣,但是效率不高、針對性不強等問題,本文提出將嵌入式數據挖掘應用于銀行卡業務中,使得應用針對性更強,在節約了開發成本的同時也提高了挖掘效率。
1 嵌入式數據挖掘模型
嵌入式數據挖掘模型主要是采用多種數據庫訪問技術把算法嵌入到數據挖掘系統中。該模型支持按照一定的標準規范來開發挖掘算法,并把算法發布嵌入到多種數據庫、數據倉庫當中,將數據挖掘過程完全控制在數據庫、數據倉庫系統中,將數據挖掘功能轉換成大家熟悉的、通用的、靈活的、可二次開發的數據倉庫功能。
該系統框架主要由數據層、算法嵌入層、數據挖掘層以及用戶層,系統模型如圖1所示。
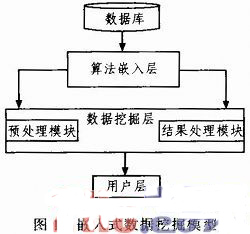
1.1 數據層和用戶層
數據層主要包括數據庫或數據倉庫中的海量業務數據以及元數據,它是數據挖掘過程中最基礎的部分。
在該模型中,用戶層包括算法發布人員、數據分析人員、數據庫管理人員,即使得數據挖掘面向更多的用戶,擺脫了以前數據挖掘對專業人士的過多依賴性。
1.2 算法嵌入層
整個嵌入流程可以分為兩個過程:算法發布和算法調用。算法發布過程主要是把算法發布到特定的數據倉庫系統中,為數據挖掘系統在數據倉庫系統中的執行奠下基礎;算法調用過程則是在數據倉庫系統中進行的,主要通過數據倉庫系統中的存儲過程,讓用戶傳人相關參數,然后調用第一步發布的算法對用戶指定的數據進行挖掘。
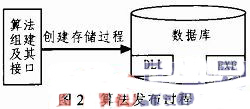
1)算法發布
算法發布過程首先就是把算法封裝成DLL文件,同時把調用算法的接口編譯成EXE文件,然后把算法DLL文件和相應的EXE文件發布到數據庫或數據倉庫中,最后在相應的數據庫中創建存儲過程(簡稱SP),流程如圖2所示。
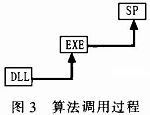
2)算法調用
在調用過程中,由于不同數據倉庫系統的存儲過程的功能大小不同,不同數據倉庫系統對EXE文件,DLL文件的調用方式都有很大的區別,所以具體的實現細節在不同數據倉庫系統下還是有很大的區別的。在該模型中,數據倉庫終端調用存儲過程(SP),把算法參數和用戶參數傳進存儲過程,然后讓存儲過程調用EXE文件,EXE文件主要是處理存儲過程傳入的參數,然后調用DLL算法生成挖掘結果。具體流程如圖3所示。
1.3 數據挖掘層
1)預處理模塊
數據預處理在數據倉庫(或數據庫)中進行,主要有兩個途徑可以實現:一種是直接利用數據倉庫管理系統(SQL等)來對數據倉庫的數據表進行加工處理,還有一種就是像挖掘算法一樣,用高級語言實現,然后嵌入到數據倉庫系統中,用戶就可以像一般的存儲過程一樣調用相應的預處理方法來對數據進行預處理。這兩種預處理可以相互循環使用,直到加工滿意的數據為止。
2)結果處理模塊
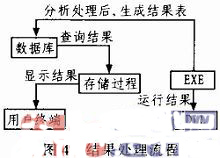
結果處理流程其實和算法凋用過程是同時進行的,在EXE文件中通過數據庫訪問技術獲取數據,在EXE中調用DLL算法產生文本結果返回到EXE文件中。這時候,這個文本結果可以經過加工處理寫回數據倉庫,同時也可以展示給用戶。具體如圖4所示。分析處理后,生成結果表查詢結果。